

前言
在说go协程之前,先对比看一下进程&线程&协程这几个基础的概念。 进程是指一段程序的执行过程,具有自己的地址空间(包括文本区域(text region)、数据区域(data region)和堆栈(stack region)),并且进程由cpu直接负责调度控制。 线程是CPU调度的最小单位,线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间。同样是由cpu直接负责调度控制的。 协程可以理解为是用户级线程,对于协程来说对内核透明的,也就是系统并不知道有协程的存在,是完全由用户自己的程序进行调度的,cpu对于我们的协程无感知。 goroutine实际上就是协程,为什么叫做go协程呢,因为go在runtime、系统调用方面对goroutine调度进行了封装和处理,也就是说go在语言层面实现对于go协程的支持:使用go 关键字就可以了。 内存消耗方面: 每个 goroutine (协程) 默认占用内存远比 Java 、C 的线程少。 goroutine:2KB 线程:8MB 线程和 goroutine 切换调度开销方面: 线程/goroutine 切换开销方面,goroutine 远比线程小 线程:涉及模式切换(从用户态切换到内核态)、16个寄存器、PC、SP…等寄存器的刷新等。 goroutine:只有三个寄存器的值修改 – PC / SP / DX. 最主要的是不担心协程间切换、或者协程打满或者夯死。 关于协程协程这类知识,感觉先说原理再说使用会比较理解,后面就先来看下go协程的实现原理。
协程实现原理
线程当前的问题主要是线程切换及夯死的问题,于是操作系统提供了基于事件模式的异步编程模型,用少量的线程来服务大量的网络连接和I/O操作。但是采用异步和基于事件的编程模型,复杂化了程序代码的编写,非常容易出错。 而协程实际上就是帮我们解决了这个问题,在应用层模拟的线程,他避免了上下文切换的额外耗费,兼顾了多线程的优点。简化了高并发程序的复杂度。也就是说协程帮我们封装了少量的线程来服务大量的网络连接和I/O操作,和线程之间的切换及服务对应服务对象的逻辑。 比如说:一个socket链接对应一个协程来处理,而这个协程具体是由哪个线程来处理及当前的是否需要处理由go来决定,这样编程就变的十分简单,并且很大程度上避免了切换的问题,也不怕一个socket夯死在那里了。
go协程实现机制
下面来看一下go协程的实现原理,go协程主要有goroutine、machine、process这几个核心概念,go其实就是在这几个概念的基础上搭建了一个go协程到cpu的调度体系。
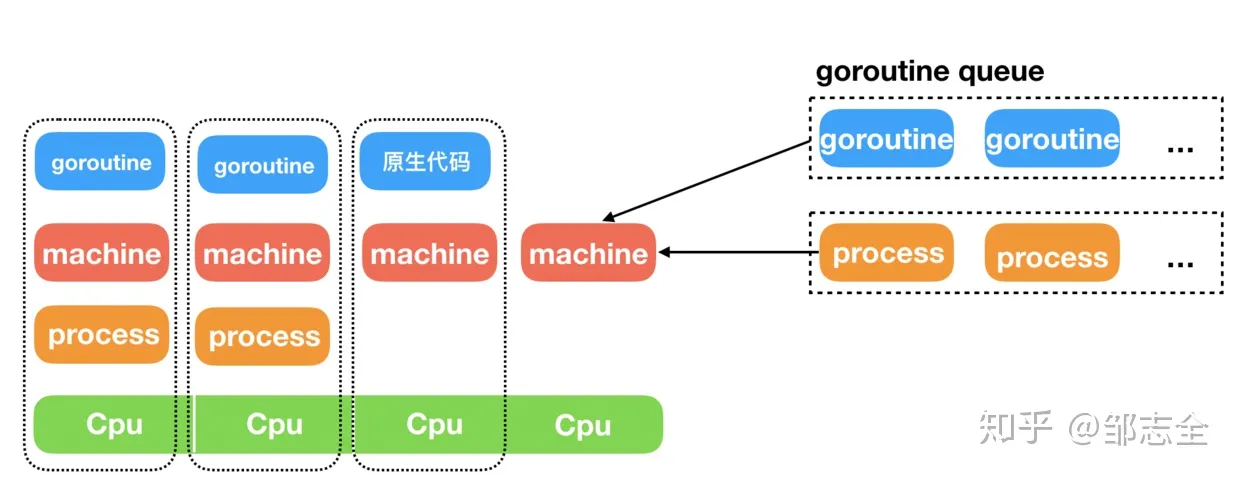
goroutine
goroutine 就是我们使用的go协程,使用go 关键字就可以了:go func1(),所有的go协程都由runtime管理(新建、恢复、停止、休眠,其中执行异步操作时goroutine会陷入休眠,不占用系统线程(这是go协程很方便的一点),当新建或者恢复时加到任务队列中) routine状态: 空闲中(idle): 新建,但未初始化 待运行(runnable): 在运行队列中, 等待M取出并运行 运行中(running): 表示machine正在执行这个routine 系统调用中(syscall): 正在运行的routine发起的系统调用 等待中(waiting): 在等待某些条件完成,不在执行也不在运行队列中(可能在channel的等待队列中) 已中止(dead): 未被使用或可能已执行完毕 栈复制中(copystack): 正在获取一个新的栈空间并把原来的内容复制过去(用于防止GC扫描)
machine
machine指的是系统线程,他是go协程中代码的具体执行者,它执行: 1、goroutine需要执行的代码(需要process) 2、原生代码(不需要process) machine会从goroutine运行队列中取出一个goroutine来执行,当执行完或者陷入休眠时,取一个goroutine继续执行,但是有些时候goroutine会调用一些原生代码会产生阻塞行为,但是无法陷入休眠,这个时候machine会陷入阻塞,但是会方式该goroutine持有的process,其他的goroutine能够拿到这个process来运行其他的goroutine。 这里的machine可以简单粗暴的理解为就是Java中的线程,而goroutine其实就是go为我们做的一层封装,其中的对应关系就是go所实现的调度策略。 如果是线程的话,不难理解,machine的数量需要保证不能太少,也不能太多,需要让cpu时刻在工作,并且不能频繁切换。 自旋(spinning): 正在取goroutine 执行态(running): 在执行代码或者阻塞的syscall 休眠中 : 当上个任务执行完,但goroutine队列中无任务时
process
上面提到了process这个概念,process指的就是machine执行goroutine时所用到的资源,这里可以看出process仅与goroutine相关,与原生代码无关。一个machine执行一个goroutine的代码时,强依赖于process,所以说如果仅有一个process,同一时刻仅有一个machine可以执行,如果有n(n小于可用cpu核数)个,同一时刻可以有n个machine可以执行。 process中的数据是lock free的,效率非常高。 process的数量通常等于cpu核数,但是两者并没有直接的对应关系,仅仅是process通常和同一时刻最多执行的machine数量相同,而同一时刻最多执行的machine也就是cpu核数罢了。 空闲中(idle): 没有被用到的process所处的状态 运行中(running): 正在执行的machine所持有process 系统调用中syscall): 当goroutine调用原生代码, 原生代码又反过来调用go代码时 GC停止中(gcstop): 当gc stop the world时 已中止(dead): 当P的数量在运行时改变, 且数量减少时,多余的process的状态
各种队列
待执行队列: 正在待执行的goroutine是存在于待执行队列中的,而待执行队列又分为本地待执行队列和全局待执行队列,加入时会优先加入本地待执行队列,取goroutine时也会优先取本地待执行队列。本地待执行队列有一个Work Stealing 机制,也就是当某一个本地待执行队列未空时会从其他本地待执行队列中取一半过来用。 本地待执行队列是一个环形队列,并且有数量限制(通常是256) 全局待执行队列是一个链表(同常规链表一样,有一个head、tail指针),保存在全局变量sched中,入队和出队存在锁操作。 空闲machine链表: 没有任务执行的machine保存在一个链表中,这个空闲链表也是存放在全局变量sched中的,空闲的machine(休眠态)等待一个信号量(m.park), 唤醒时会使用这个信号量。 所以说machine大致分为这么三类:正在执行的machine、在空闲链表中的machine、自旋状态的machine 为了保证有足够的machine来执行goroutine: 1、有新的goroutine, 如果当前无自旋的machine但是有空闲的process, 就唤醒或者新建一个machine。 2、当machine准备运行出队的goroutine时, 如果当前无自旋的machine,但是有空闲的process, 就唤醒或者新建一个machine 3、当machine离开自旋状态并准备休眠时, 会在离开自旋状态后再次检查所有运行队列, 如果有待运行的goroutine则重新进入自旋状态,并进入竞争态。
因为”入队待运行的G”和”M离开自旋状态”会同时进行, 为避免待运行的goroutine入队了, 也有空闲的process, 但无machine去执行的情况,go会这样去检查: 1、入队待运行的goroutine 内存屏障 2、检查当前自旋的machine数量 3、唤醒或者新建一个machine 4、减少当前自旋的M数量 内存屏障 5、检查所有运行队列是否有待运行的goroutine 6、休眠 空闲process链表: 空闲process链表用于保存空闲的process,保存在全局变量sched中。 上面提到的一个sched本质上就是一个调度器,定义在proc.c中。 关于更多的实现细节,还有更加详尽的源码剖析和底层汇编发生了什么可以参考一下这篇blog(文章写的非常好,力推): https://studygolang.com/articles/11627 上面提到的work stealing 实际上是一个调度算法,详细的大家可以看一下这篇论文。 http://supertech.csail.mit.edu/papers/steal.pdf 关于go协程的介绍,本篇暂时就先介绍这么多。
