上一篇说了Kafka consumer的处理逻辑、实现原理及相关的特点,本篇来看看Kafka 另一个client Consumer,作为生产者消费者的另一端,consumer提供了消费消息的能力,下面来看看Kafka中的consumer 应该如何正确使用及实现原理。
发布订阅&生产者消费者模式
常见的消息引擎中通常有 经典的生产者消费者模式、发布订阅模式 两种
生产者 消费者模式
是一种点对点的方式,消息不会被重复消费,可以粗暴的理解为消息被消费后就被标记删除或者已删除了,这是常见的消息队列通常的模式。比如说进程间通信,这种基于队列实现消息传输服务的。
发布订阅
相对于生产者 消费者模式,消息可能会被多方消费,可以简单的理解为一份报纸的内容,订阅它的人都可以读到它,当一个人读完之后也就没必要再次去读了。并且在发布订阅模式中,通常有个概念叫做topic,每个topic 有对应的发布者(publisher)、订阅者(subsciber)。
那Kafka是如何实现生产者消费者两种模式的呢?往后看~
消费者 & 消费者组
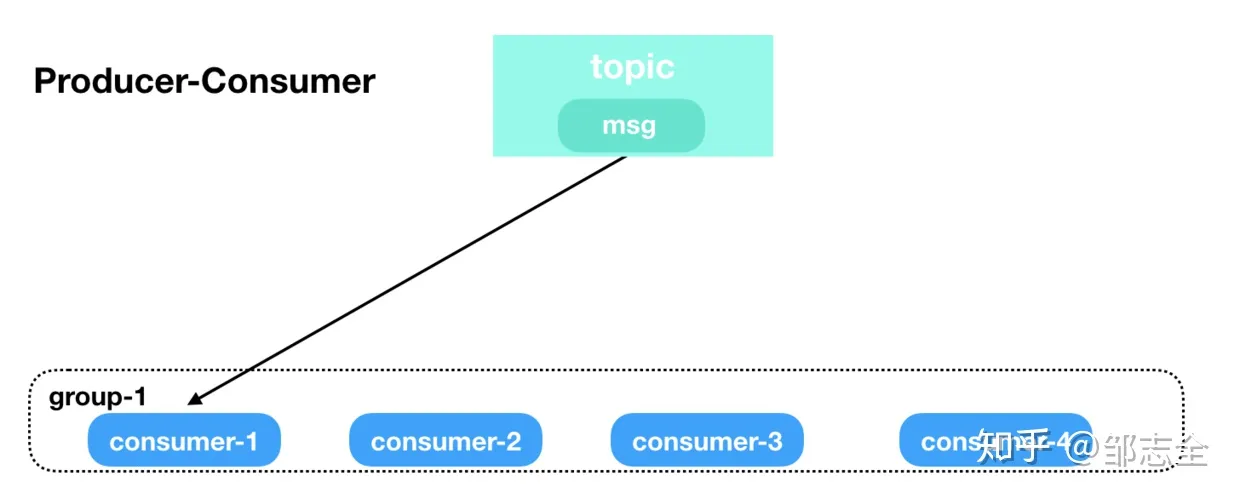
kafka中有一个概念叫做consumer group,每个group 去订阅对应的topic,topic的每条消息只能发送到订阅它的消费者组的其中一个实例上,并且每个消费者至多使用一个消费者组来标示自己。这样不难得出,当某个topic 仅有一个group来消费时(组内有一个或者多个consumer),这个topic的消息的消费模式就是典型的生产者消费者模式。
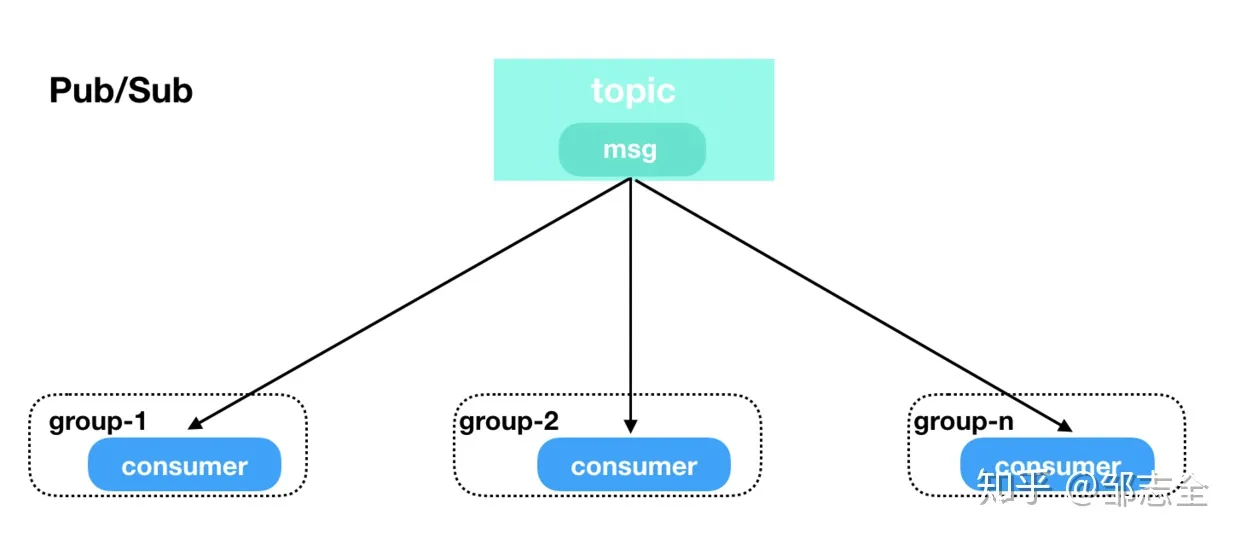
而当某个topic 被多个消费者组订阅,而每个组仅有一个消费者时,每条消息就会被广播到每个消费者上。
这里需要注意下,还有个叫做独立消费者(standalone consumer)的概念,对于consumer group 是以group 为单位进行消息消费的,而standalone 会单独的执行消费,以consumer 实例为单位进行消费的。
group 状态机 & group管理协议
是时候来看看Kafka consumer 端的实现原理了,先从最基础的group 开始,当前较新版本的consumer是依赖于broker端的coordinator来完成组的管理的(主要是把分配方案通知到每个consumer实例上),当然了这里涉及一个一致性策略,当无法达成这个策略是,就直接抛异常请求人工介入处理了。
coordinator 实现组的管理,依赖的主要是consumer group的状态,仅有 Empty(组内没有任何active consumer)、PreparingRebalance(group 正在准备进行rebalance)、AwaitingSync(所有组员已经加入组并等待leader consumer发送分区的分配方案)、Stable(group开始正常消费)、Dead(该group 已经被废弃)这五个状态,那他们是如何轮转的可以简单的看一下状态机。
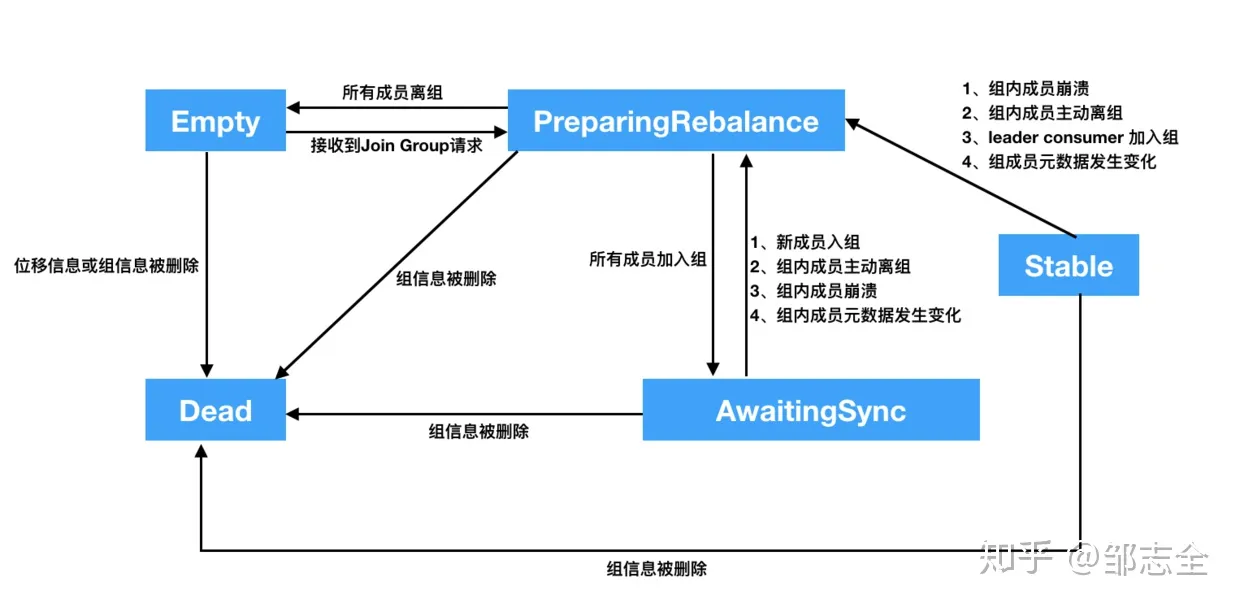
就整个过程来说,可以大致分为加入组阶段、状态同步阶段。
加入组阶段:当明确group的coordinator之后,组内成员需要显式的发送JoinGroup请求(主要包括 订阅信息、成员id等元数据信息)给对应的coordinator,然后coordinator选择对应的consumer 作为leader,然后再给其他成员产生响应(一个空数组)。当然啦,如果某个consumer 指定的分配策略是其他consumer 不支持的,那么这个实例是不被接受的。现有的分区策略主要有:range、round-robin、sticky,其中sticky是其中可以最大限度保证分区的负载的均衡分配机rebalance之后的最少分配变动。
offset & broker 中的offset
offset 概念这里需要单独抽出来说一下,因为在Kafka 里面存在两个offset的概念,一个指的是consumer 中的offset,一个是broker中的offset
concumer offset 用来记录当前消费了多少条消息,这个offset的状态是由consumer group来维护的,通过检查点机制对于offset的值进行持久化(内部就是一个map)
broker offset 消息在broker 端的位移值,根据之前说过的几个概念可以大致的理解为一个可以唯一的标示到一条消息。
_consumer_offset topic & zookeeper 位移管理
因为新版本和旧版本Kafka 所采用的offset保存策略是不同的,旧版本中主要依赖于Zookeeper,但是zookeeper不是干这事儿的啊,所以kafka 在数量很大的消费发生时,zookeeper读写会异常的频繁,导致很容易成为整个Kafka系统的瓶颈。所以新版本对这种方式作出了重大更新,不再依赖于Zookeeper 来进行状态的保存,而是在broker 端直接开一个内部使用的topic,也就是_consumer_offsets topic,并且kafka 为了兼容老版本的consumer 还提供了 offsets.storage=kafka这样一个适配参数。
Rebalance & 场景剖析
最后要说的一点就是consumer 端的Rebalance 过程(rebalance是针对consumer group来说的,如果是standalone consumer 则没有这个概念),rebalance也就是如何达成一致来分配订阅topic的所有分区。这个rebalance的代价还是不小的,我们是需要避免高频的rebalance的。常见的rebalance 场景有:新成员加入组、组内成员崩溃(这种场景无法主动通知,需要被动的检测才行,并且需要一个session.timeout 才检测到)、成员主动离组。
consumer 是可以执行任意次rebalance的,为了区分两次rebalance上的数据(防止无效或者延迟的offset提交),consumer 设计了一个叫做rebalance generation的标示。
对应常见的rebalance请求有:
JoinGroup:consumer 请求加入组
SyncGroup:group leader把分配方案同步给组内所有成员
Heartbeat:consumer 定期向coordination汇报心跳表示自己还存活
LeaveGroup:consumer 主动通知coordinator该consumer即将离组
DescribeGroup:查看组的所有信息。
Consumer端常见的概念大致就这么多。Kafka-consumer-解析