

前言
最开始在Kafka 概述中提到了mirc-batch(微批处理),mirc-batch是Kafka 高性能的一个非常重要的原因,这一下子就使Kafka 成为了一个拥有近乎流式处理框架的的高吞吐级别,但是mirc相对于流式处理还是存在很大差异的,但是一些所谓的流式处理框架使用的也有mirc-batch(比如说spark Streaming),当然啦一些正统的流式处理框架,比如说storm、Flink使用的都是典型的流式处理。 本文按照 批处理、微批处理、流式处理来说一下为什么Kafka选择了micr-batch。 在介绍之前先说一下几个经典概念:
响应时间:
响应时间通常是评定一个系统或者网站最直观的感受,狭义上来说响应时间是指系统对于请求作出响应的时间,但是现在对于响应时间有了更多表现,比如说前端的首屏加载时长等,也是对于响应时间的综合表现(不仅是一个单系统服务,更多是各方综合的结果)。
吞吐量&高吞吐:
吞吐量最直观的概念是指系统在单位时间内所处理请求的数量。对于无并发的系统,吞吐量和响应时间是严格的反比关系。历史上并发的出现打破了这个规律,也为提升吞吐量带来的新的生机。对于单用户系统来说,可能响应时间是最重要的,而对于现在互联网大多数服务而言,吞吐量可能是最重要的(当然啦可用性什么也非常重要)。所谓的高吞吐就是说可以持有非常高吞吐量的一个表现了。
时延
标准的定义是指数据经过网络或者链路从一端到另一端的所消耗的时间,时延其实是分很多种的,发送时延、传输时延等,但是其实概念基本上是类似的,从一个点到另一个点,这个点可能是状态也可能是操作与操作之间的时间间隔,在kafka中所指的通常就是消息时延,这个特性对于一个消息系统来说是十分重要的,比如producer所能提交消息的速度。这个在kafka里和吞吐量是十分相关的。
时延和吞吐量通常是无法同时兼顾的,我们在提升一个指标的同时,可能要牺牲另一个,所以要根据具体的业务场景来做一个衡量。
批处理
批处理是指一改当初串行处理的模式,作业出现后就立马进行处理,而是说按批次对于作业(请求)进行处理。批处理具有一个典型的特点,就是吞吐量高,CPU利用率十分出色。具体来说就是把具体的要处理的数据(作业 || 请求)按照性质或者某些属性进行分组或者分批,再成组或者成批的提交到对应的计算系统。批处理出现的非常早,回一下当初的操作系统可能就对于早期的多道批处理系统&单道批处理系统有印象了。 通常来说,批处理是一种将作业提交给计算系统后就不再干预,通常是非常低的交互性或者根本无交互性可言。业界有非常多经典的实现比如说Hadoop(MapReduce) 计算,根据系统的特性,我们通常会发现批处理所处理的作业或者数据都是些庞大并且离线已经存储好的数据(有界、持久、海量),都是些对实时性几乎没有什么要求的场景,比如大数据报表的生产、模型的训练。
流式处理
流式处理是指对于随时可能进入系统的数据进行计算处理,相对于批处理来说算是种截然不同的处理方式,无需正对整个数据集进行计算操作,而是说来了就干,实时性非常好,处理速度快,结果立马可用,同一时间仅处理一条数据。 常见的流式处理框架有storm、Flink(Spark Streaming 严格意义上来说不算是流式处理),流式处理通常用于,分析监控对实时性要求非常高的系统的错误日志,或者其他以时间为衡量标准的数据流。
微批处理
micr-batch 是一种借鉴了批处理及流式处理的特性,针对吞吐量及时延做了下兼顾(通常是适当的损失时延 来提升吞吐量)。批的数量或者规则不再那么大,而是划分为小批次或者微批次,从而提升吞吐量的同时,对于时延方面,别做出那么大的损失。
来看看Kafka的实现,因为是一个实时的消息系统,所以说纯粹的批处理不现实,比较下单纯串行处理方式吞吐量又不够,所以Kafka 采用了micr-batch的处理方式。重新来看看这张producer的图:
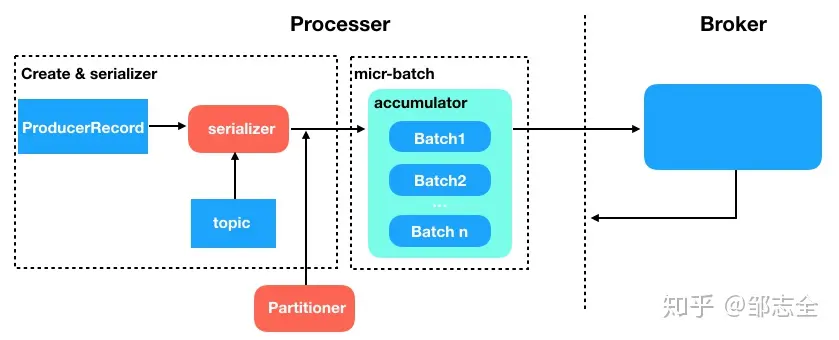
在producer端消息被生产之后并不是直接发送的,而是在accumulator上缓存一下,然后集中发送出,这样就简单的实现了micr-batch,那带来的改善是什么样子的呢?继续看
比如说Kafka处理一条消息需要2ms,那么对应的吞吐量最多500,时延为2ms。
现在把Kafka 消息不立即发送而是说等一等一块发,等大约8ms,假设这段时间积攒了500条消息。
看一下吞吐量的变化 :5000/(0.002s +0.008s)=50000,提升了大约100倍,如果积攒的消息数量是100条,那么带来的提升就可能是200倍,这个跟kafka producer 消息的生产速度是非常相关的(决定了所能带来的提升,需要根据具体的场景来确定等待的数量,这里producer是通过对应参数来控制的:
batch:
buffer.memory 指定producer待发送消息缓冲区的内存大小,默认32m,如果需要更改就使用这个参数进行修改。这里需要注意的是当producer端写消息的速度超过了专属IO线程发送消息的速度,并且缓冲区的消息数量超过buffer.memory指定的大小时,producer会抛出异常通知用户介入处理,这个缓冲区的大小需要根据实际场景来确定。
batch.size 指一个batch的大小,它直接决定了一个batch中存在的消息数量,这个直接与producer的吞吐量及延时等直接相关。
linger.size
producer端会专门划出一部分内存用于待发送消息的缓存,batch.size决定了发送消息数量,同时间接决定了消息缓存时存在的延时。linger.size 就是针对这一点设计出来的,它决定了消息被投放进缓冲区时是否立马被发送,默认参数是0(立即发送),这个大多数情况下是合理的,但是会很大程度上拉低kafka的吞吐量。
关于上述的一些处理特性,我们除了需要了解之后更好的去使用Kafka,感觉更需要学会这种解决问题的思路,对于一些需要吞吐量的场景也可以去借鉴这种micr-batch 的实现。Kafka-“高性能”-mirc-batch
