Kafka 支持的压缩算法还挺多的,这一篇来站在Kafka的角度看一下压缩算法。就当前情况来说,支持GZIP、Snappy、LZ4 这三种压缩算法。具体是通过compression.type 来开启消息压缩并且设定具体的压缩算法。
props.put(“compressions.type”, “GZIP”);或者
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, “GZIP”)压缩算法是要占用挺大一部分cpu资源的并且耗时也是不小的,而压缩的目的很大程度上是为了提升网络传输的性能,毕竟小点传得快嘛。但是整个压缩的过程也是很耗时的,通常来说KafkaProducer.send( )主要时间其实都花在在压缩操作上,如果压缩的过程十分漫长,那么压缩就显得有点多余了,所以选择一个高性能的压缩算法是十分关键的。而且就现状来说对于Kafka这种消息系统瓶颈往往不是CPU,通常来说都是受网络带宽。
下面来看看GZIP、Snappy、LZ4 这三种压缩算法
GZIP
GZIP是GNUzip的缩写,最初是用于UNIX系统的文件压缩,常见的.gz的压缩文件就是gzip所压缩得到的,通常来说,对于纯文本内容,可以压缩到原大小的40%来进行传输,Java 实现的gzip 和 unix下的gzip 压缩效率和压缩率是很相近的。
Snappy
Snappy是谷歌开源的一个压缩/解压库,其实Snappy的压缩率挺一般的,可能比我们常见的压缩算法压缩率都要差,但是Snappy 对于Kafka 这种消息系统来说有一个显著的优点,它的压缩速率基本上是第一的。最初的设计目的就是用来平衡压缩时间与压缩率的的,对于一些常规的文件,多那么1、2 k但是要多花那么几毫秒,其实还挺得不偿失的,在Snappy最初推出的时候所重点宣传的其实就是压缩速率而非压缩率。
LZ4
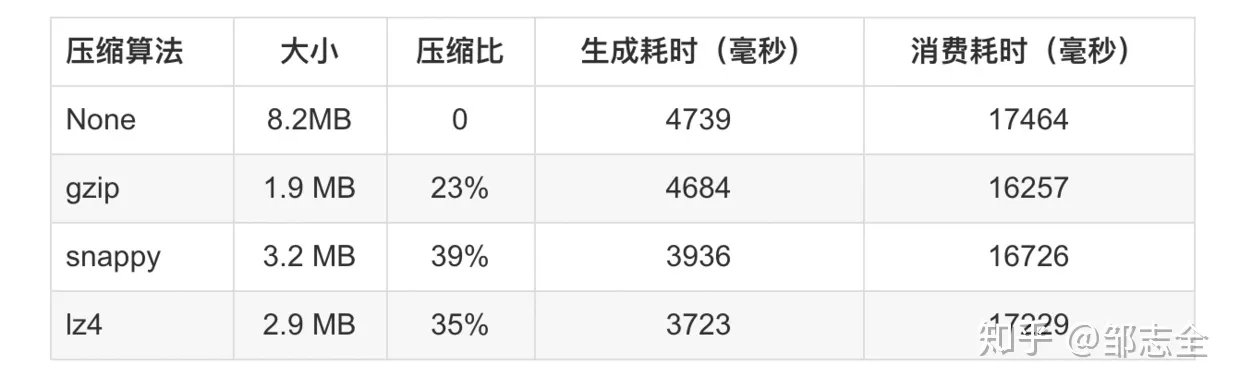
LZ4其实和snappy的初衷是相同的,但是LZ4追求压缩速率的同时相对于snappy来说,不仅压缩更快了,压缩率也更佳可观了,同样是谷歌开发的。去看LZ4相关介绍的时候,提到了LZ77,博主是这么介绍LZ4的:LZ4就是一个用16k大小哈希表储存字典并简化检索的LZ77,而LZ77是一个应用了字典来进行压缩的算法。通俗来说,就是让程序观察(看字典)当前看到的数据是否和之前有重复, 如果有的话,我们就保存两个重复字段的距离(offset)和重复的长度,以替代重复的字段而以此来压缩数据。 其中LZ77 最大的缺陷是在字典中寻找待匹配的最长的字符串占用了大量的时间,如果字典和待搜索的缓存过短,能匹配到的概率就会非常小,针对这个问题LZ4做出了自己的改进,从而进一步的提升了压缩速率。 因为我对压缩算法也不是很熟悉,只能概要的介绍一下,推给大家,还请见谅,以后有机会仔细的来看这些压缩算法,下面是几种算法的一个比较,然后Kafka是按照batch对消息进行压缩的。
然后接下来Hash算法,Hash算法在Kafka 中被用来作为具体的分区选择,这决定分区的选择是否公平、分配到的各个分区的消息和请求书是够均衡。
Kafka 中使用的Hash算法叫做murmur2,murmurHash是一种比较先进的非加密Hash算法(主要还是用来Kafka这种选择的场景),当前最新的版本是murmur3,它能在有规律的输入时也能保证分布较为均匀,使用这个算法的还有redis(当字典被用作数据库的底层实现或者hash键的底层实现时,来计算键的哈希值)、nginx、Hadoop。然后说到Hash,Java 中最常见的HashMap 采用的xors hash。
我们经常在一些场景中听到加密Hash 或者 不加密Hash这样的一些词儿,有时候感觉一些Hash散列算法就是加密,其实这方面是存在一些界限的。准确来说Hash算法是一种消息摘要算法,不是一种加密算法,但是因为Hash算法的单向运算(存在一定程度上的不可逆性),所以经常被用来作为加密算法中的一个重要构成部分,但是完整的加密算法远不止Hash算法(通常来说,加密算法是可逆的),除了加密算法,Hash本身最适合的场景其实是HashMap、Kafka分区选择这种选择的场景。
这一篇说了一些概念和个人的见解,不是很熟悉,见谅。