

map通常是一种无序键值对的集合,map存在的意义主要是利用map的结构根据key来快速检索数据,在go中也是这样的。 map 也是一种集合,我们可以像遍历数组或者切片一样遍历它,但是需要注意的是map是无序的。
语法
声明:
var mapTmp map[string]string
定义:
var mapTmp = map[string]string{"address":"123"}
mapTmp := map[string]string{"address":"123"}
var mapTmp = make(map[string]string)
设置值:
mapTmp["address"] = "456"
删除值:
delete(mapTmp, "address")
go map实现
map 通常是是一种key – value结构,然后根据key(索引)来查找value。通常的实现有这么几种TreeMap、HashMap等。 C++ 中的实现是基于红黑树的(相对于C++ 实现的其他map,性能稍低但稳定性好),通过模版在编译器生成代码,性能更好,但是很容易代码膨胀,因为发生在编译期,编译时间也会随之上升。 Java 中的map实现比较丰富:HashMap、TreeMap、LinkedHashMap,这里拿和go实现较为类似的来看,Java 中的HashMap 是由hash table + 链表/红黑树(链表长度大于8时扩展为红黑树),java 中的map同样仅使用一份代码,但要求map的key必须是Object的子类。 最后来看Go的实现,go 采用的是hash table + 链表实现的,使用链表来解决hash冲突问题,通过编译器配合runtime,所有的map 共用一份代码。
hash算法
Hash算法是hashmap 中非常关键的一点,通常来说有性能&碰撞概率两个重要的方面,而这两个方面直接决定了一个map的性能。 Hash算法有非常多,通常来说分为加密型和非加密型。 加密型:md5、sha1、sha256、aes256(通常来说比较慢,但碰撞可能性非常小) 非加密型:Java hashmap 用的是XORs,Kafka 用的是murmur2(性能好,较高的碰撞概率) 而go就比较厉害了,根据硬件来选择具体的hash算法,如果cpu支持aes则使用aes,如果不支持则使用memhash。具体各种Hash 算法的差异,大家可以自己查一下,资料非常多。其中把hash值映射到buckte时,go会把bucket的数量变为2的次幂,而有m=2^b,则n%m=n&(m-1),用位运算规避mod的昂贵代价。
源码分析
go map的源码在/src/runtime/map.go 一个map主要由 1、hamp(map 外层结构,包含大小、bucket等基础信息) 2、mapextra(记录map的其他信息,比如说overflowbucket) 3、bmap(一个bucket,每个bucket最多能存放8个key-value)
// A header for a Go map.
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
// mapextra holds fields that are not present on all maps.
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}
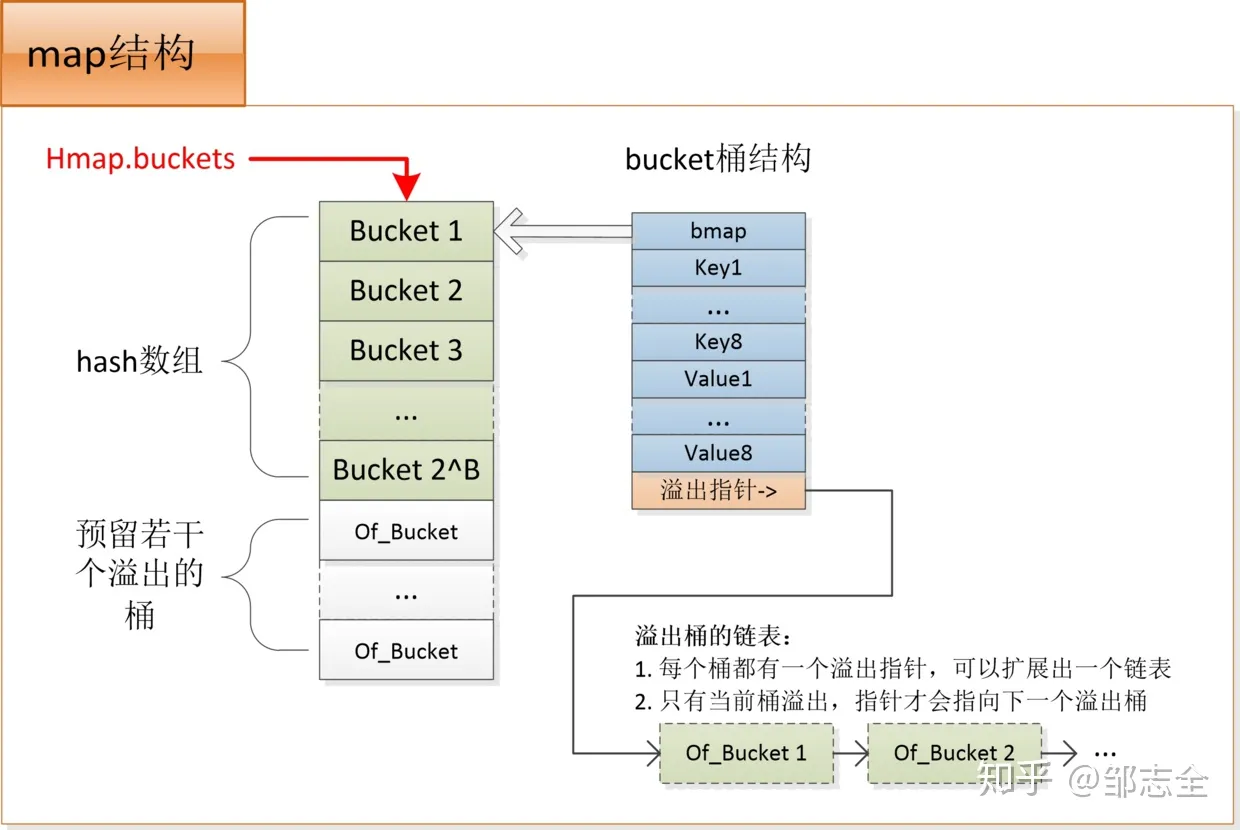
核心逻辑就是bmap: 1、当出现hash冲突时,而是以bmap为最小单元挂载冲突的元素,本来bmap的数量就不大,这样设计能更有利于GC。 2、当一个bmap 满了之后,会优先使用预分配的overflow bucket,如果预分配的用完了,就malloc 一个挂上去。 3、bmap中hash值的高8位存储在tophash字段中。把高八位存储起来,这样不用完整比较key就能过滤掉不符合的key,加快查询速度。实际上当hash值的高八位小于常量minTopHash时,会加上minTopHash,区间[0, minTophash)的值用于特殊标记。
扩容设计: 不断的设置key-value,bucket上为了解决冲突用的链表必然会越来越长,性能也就随之下降,为了性能考虑我们会进行扩容。 1、扩容时机 当bucket/bucket中元素的数量>=6.5时,会将bucket扩容为之前的两倍(bucket的容量是恒定不变的) 2、扩容方式 go map的扩容不是在一次insert时就一次性完成,而是逐步完成的,这样的目的有两个: 1、分担扩容带来的时间损耗。 2、避免扩容期间,某个bucket一直无法访问,导致扩容无法完成。 扩容方式遵循顺序扩容,每次写操作迁移对应的bucket的同时顺序迁移bucket来保证n次写操作完成就能完成n个bucket大小的map。 其他源码,比如说创建、查询、删除等,可以看一下go的源码,这里就不过多描述了。 go map暂时就这么多。
