

前言
上一篇介绍的ISR的不丢消息的种种备份及冗余机制的所有的核心逻辑都是围绕着HW值、LEO值来展开的,如何合理的更新和存储显得尤为重要。
首先简单的看一下LEO HW之间的一些基础概念及关系: HW:replica高水印值,副本中最新一条已提交消息的位移。leader 的HW值也就是实际已提交消息的范围,每个replica都有HW值,但仅仅leader中的HW才能作为标示信息。什么意思呢,就是说当按照参数标准成功完成消息备份(成功同步给follower replica后)才会更新HW的值,代表消息理论上已经不会丢失,可以认为“已提交”。 LEO:日志末端位移,也就是replica中下一条待写入消息的offset,注意哈,是下一条并且是待写入的,并不是最后一条。这个LEO个人感觉也就是用来标示follower的同步进度的。
LEO:
存储:
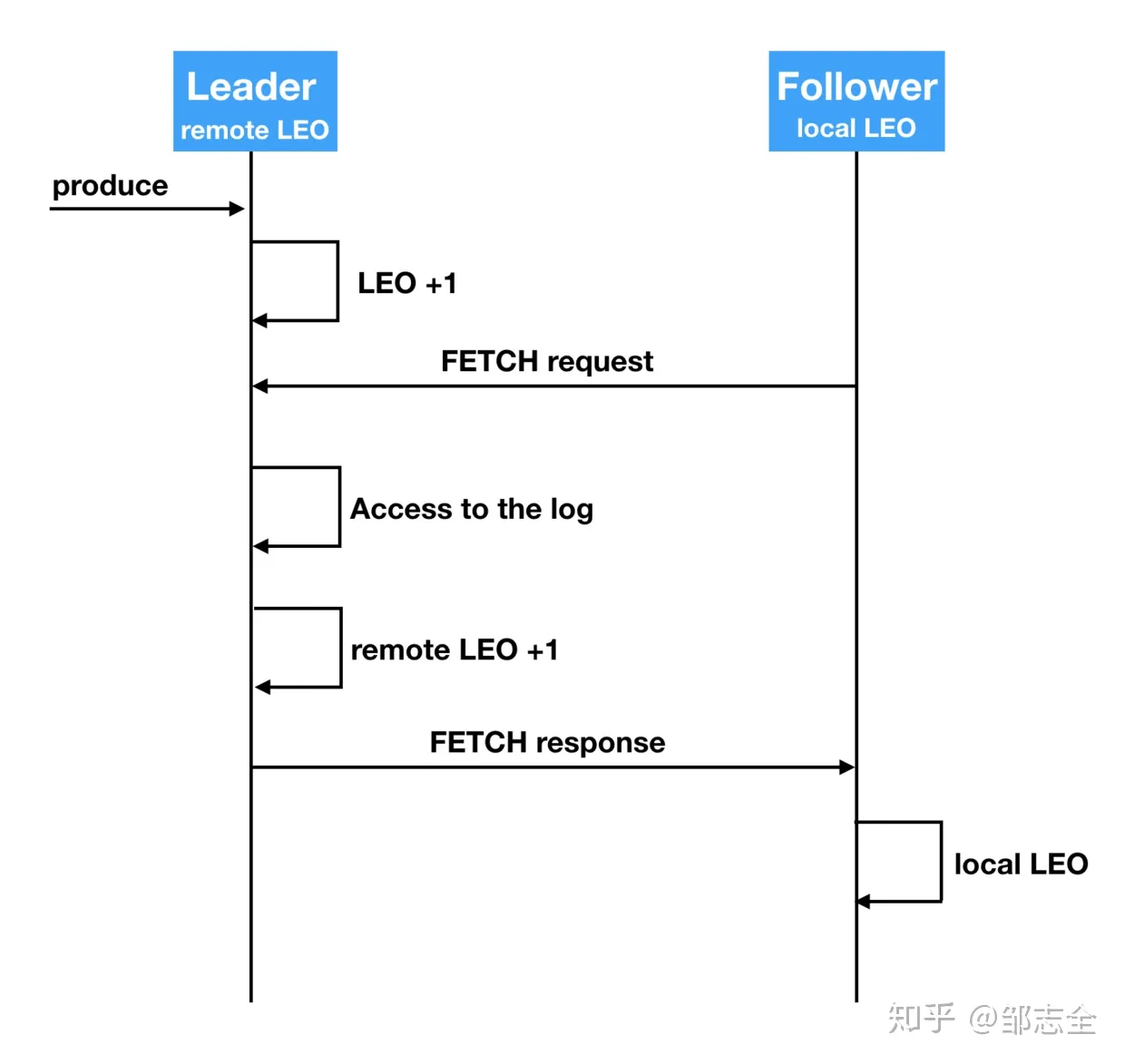
在Kafka 中是存在两套follower信息的,一套存放在follower所在的broker的缓存上(local LEO),另一套LEO值保存在leader副本所在的broker 缓存上(remote LEO)。这样设计的原因是 需要使用LEO来更新自身的HW值,利用remote LEO来更新leader 的HW值。
local LEO更新:
本地LEO值,是依赖于实际消息的消息写入来更新的,follower发送FETCH请求并得到leader的数据响应时,每当一条消息写入底层日志成功那么local LEO就+1。
remote LEO更新:
上面看到了follower local LEO值更新是发生在FETCH请求成功响应且消息成功写入时,而remote LEO 也就是leader上存储的follower LEO,是在这个环节之前,在收到请求之后拉取对应的消息log,响应之前来更新remote LEO的值的。
HW更新
follower HW 更新遵从最开始说的那个规律,在日志成功写入,LEO更新之后,就会尝试更新自身HW的值的,这个尝试发生在收到FETCH响应时会比较本地HW值和leader中的HW值,选择小的作为自身的HW值,所以说follower的HW值。但是follower 的HW值,说实话并没有什么卵用,说到用处的话应该是为称为leader做准备吧。相对来说leader 的HW值才是业务中所关心的,它决定了consumer端可消费的进度。
前面提到了,在producer 产生消息并且LEO成功更新时,HW的值可能会尝试更新(这需要根据ISR的同步策略来确定),然后还有leader在处理FETCH的请求时也会尝试更新。另外还有就是follower时、某个副本被提出ISR时都会尝试更新对应的HW值。这四种情形里面,最常见的就是接受FETCH请求时,通过比较自己的LEO值与缓存的其他的follower的LEO值,选择其中最小的LEO值来作为HW值,所以说HW值实际上就是ISR中最小的副本的LEO值啦。
其中leader 是通过follower 的offset来确定follower上次的消息是否写入的,所以就导致,remote LEO是比leader LEO小1的(更新remote LEO更新的其实是上次操作的结果),这就导致了如果最后一个follower同步完成时,HW实际上是未被更新的,得等到第二次FETCH请求才能完成HW的的更新(也就是说 第一轮FETCH完成了消息的同步(但leader 对于folllower是否成功保存毫不知情),第二轮完成了消息同步的同时完成上一轮的HW值的更新)
需要两轮请求还完成HW值的更新,很容易就出现备份数据不一致的问题,但是这个问题是很容易理解的,因为在最大程度上保证正常情况下 消息成功保存后才完成状态的更新从而保证消息不会丢失。
具体来说是这样的一种情况,首先很多时候是leader 成功写入消息就完成对于producer的成功写入响应的,在这种情形下当完成第一轮写入,成功返回后follower 挂掉了,然后HW未更新,当重启时会做日志截断,所以实际上HW值是比leader小的,然后正要同步消息的时候,leader挂了,然后刚才重启的follower成为了leader,之前的leader 重启后就会更新HW值为最小值,所以就导致了刚才那条消息的丢失。通常就是这种轮着宕机轮着重启情况下才会出现的问题,虽然极端,但还是有这个风险。
上述是指0.11.0.0版本之前的所使用的方式,新版本已经针对这个问题完成了修复,但是低于0.11.0.0仍然是生产环境中使用较多的,所以这个问题需要知晓。
0.11.0.0之后的版本就比较简单了,直接使用leader epoch(在副本上直接开辟一个内存区域)来保存对应的成功持久化的进度,来替代之前的HW值。而这个epoch实际上就是一个的二元组,每当leader 写入消息成功时,更新epoch后才会成功响应,当副本成为leader时就会去检查这部分数据,获取对应leader的位移,从而保证了不会产生上述不一致的情况,相当于引入一个pffset值来做了更深一层的一致性保护。源码可以简单看一下Kafka.server.checkpoints.LeaderEpochCheckpointFile 检查点实现。
ISR新老版本的消息同步策略基本都在这里了,大家对于整个消息的保存策略、内部消息同步策略、消息交付语义的保证应该有了一定程度上的认知啦。


