

前言
上一篇所说的micr-batch 其实主要是针对producer 来实现的,Kafka整体吞吐量高可不只是依赖于micr-batch这一点,还有broker端及consumer端。
Kafka高吞吐的另一个依赖因素是磁盘的高速读写、sendFile 的零拷贝,顺序访问避免了磁盘IO速度缓慢的问题。而零拷贝直接降低了网络IO的代价。下面就详细的来看看关于操作系统层面上顺序读写&速随机读写的一点现状、所谓的零拷贝技术。
与其说是Kafka 的文章,其实更像是对于Java JVM 或者 操作系统关于磁盘&文件的一种剖析:
操作系统常识
首先我们磁盘是由具体的盘片所组成的,每个盘片有两个盘面,然后盘片上有个主轴,围着主轴有一些磁道,然后同一个磁道被划分为若干个扇区,其中扇区之间有间隙隔开(间隙占10%左右),普通磁盘用的都是机械操作,外磁道和内磁道的角速度相同,所以说内磁道速度其实是小于外侧磁道的,所以通常来外磁道密度较小,然后读取速度就基本一致了。再然后,拥有相同磁头的磁道组合在一起称为一个柱面。磁盘的读取时间主要花在,循道时间、旋转延迟、传输时间上,一个7200r/min的磁盘,通常在一个磁道上的读取时间是10ms级的,异常慢。
顺序访问
顺序读写&随机读写做下差异比较的话,普通磁盘的顺序访问速度跟SSD顺序访问速度差不多一致,远超随机访问的速度(差不多 *2 +),甚至能达到内存随机访问的速度(这里举的例子是指SAS磁盘),随机读写相对于顺序读写主要时间花费在循道上,并且顺序读写会预读信息,所以速度自然就差异很大了。
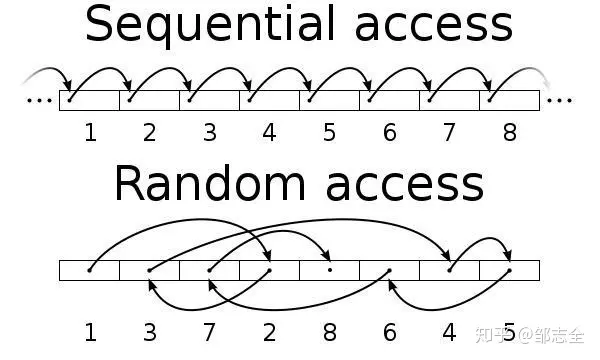
鉴于以上原因,Kafka 采用的文件追加写入的方式,所以效率自然而然就上来了。这可能也是Kafka设计存储方式采用消息日志文件的原因,总体来说,这种写入之后就不会变,并且会大量读写操作的场景都可以使用这种方式的。在关于producer 产生消息 broker底层读写日志采用的就是这种方式,有没有很方便呢~
然后再来看看消费消息时所用到的FileChannel.transferTo函数,FileChannel是一个接口,具体的实现逻辑在FileChannel中,有兴趣的可以大体的看一下。在JVM层面这个其实就是linux 中的sendFile 系统调用。
sendFile
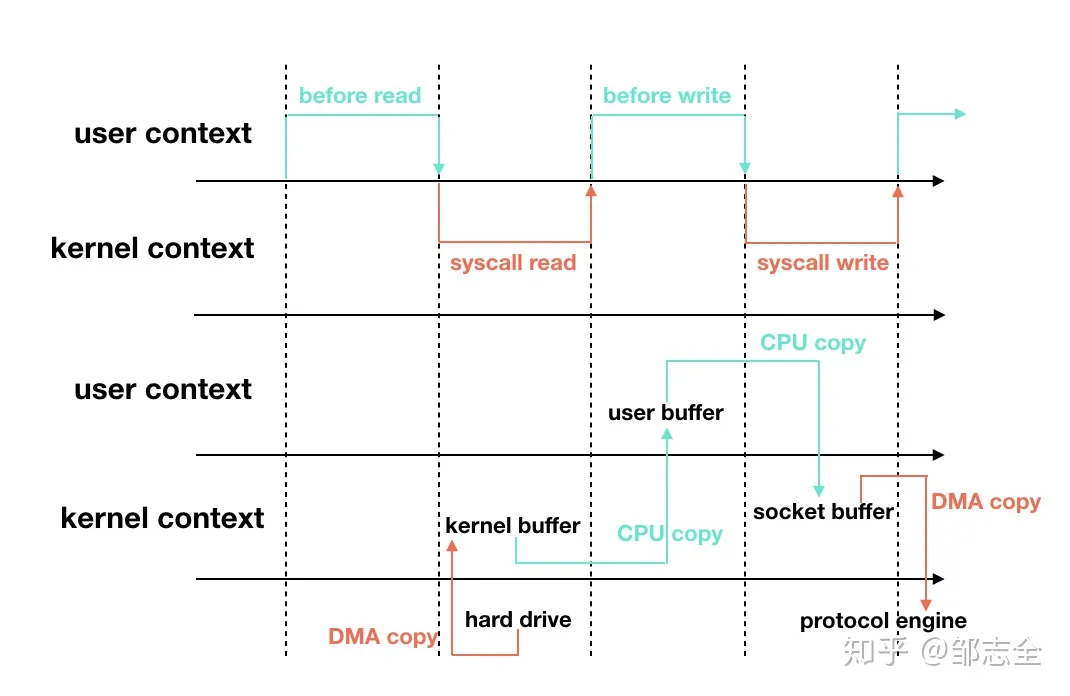
关于sendFile,其实就是原本一份数据的IO是需要经过多次copy操作&内核态与用户态的上下文切换,读内核态缓存到应用程序缓存在从应用程序缓存到Socket缓存完成具体的IO操作,而sendFile系统调用零拷贝就是避免了上下文切换带来的copy操作,同时利用直接存储器访问技术(DMA)执行IO操作,避免了内核缓冲区之前的数据拷贝操作。上升到上层的语言操作,就是使用的Java中的FileChann el.transferTo方法进行实现的。(Kafka 1版本使用的是Scala,2版本开始就是使用Java 了这两者都是在JVM上执行的,本质.class 文件解析执行阶段其实是一致的)
无零拷贝的过程:硬盘 -> 内核buffer -> 用户buffer ->内核socket缓冲区 -> TCP 协议栈
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count)in_fd被打开是等待读数据的fd.out_fd被打开是等待写数据的fd.Offset是在正式开始读取数据之前应该向前偏移的byte数.count是需要在两个fd之间“搬移”的数据的byte数.
当使用sendfile零拷贝时:硬盘 -> 内核 -> TCP协议栈
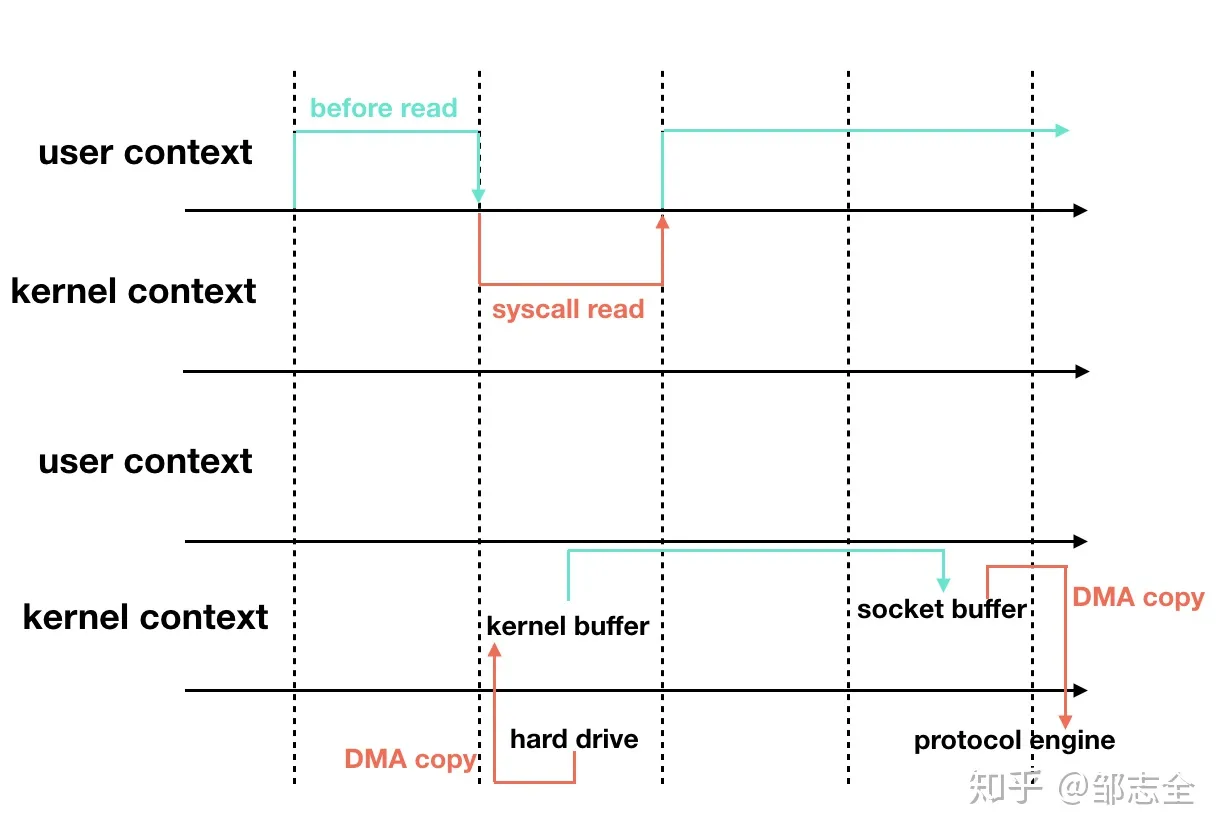
这就避免了内存切换之间的数据拷贝问题,相应的效率也就上升了,具体过程差不多就是这样。Kafka-“高吞吐”-之顺序访问与零拷贝

