

前言
就营销活动搭建的发展过程而言:最初的营销活动的搭建通常是“定制化”的,面临一个需求、一个场景写一个活动,慢慢的重复性活动越来越多,开始借鉴模板的思想,制作几套活动开始每次换肤,但是次次换肤限定了玩法套路,容易导致用户疲劳,效果开始衰退。
这时候活动的诉求已经变成在现有的模版思想上灵活串联现有玩法,并不断新增玩法,所以开始沉淀一个又一个的标准“玩法”,比如说任务、签到、抽奖、投票、答题、助力、组团、打榜等等若干玩法,然后每次有新的活动我们只需要手动开发串联即可。
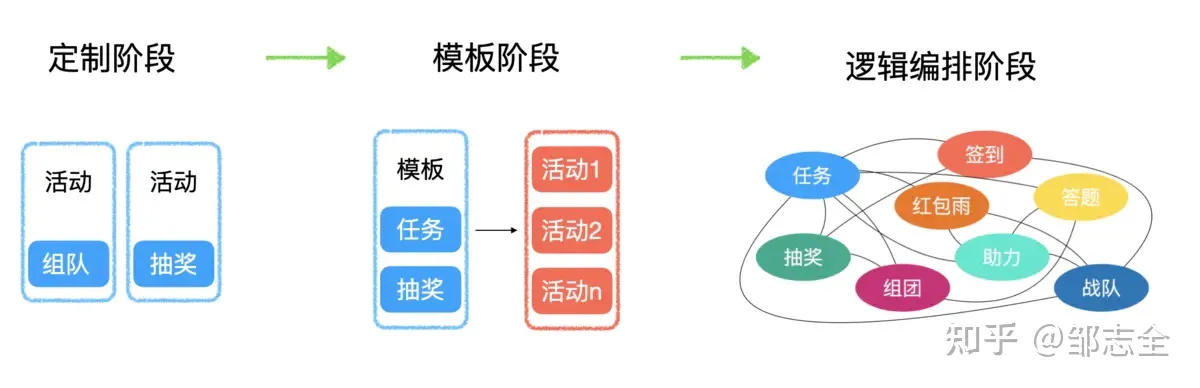
整个的对于玩法的串联,可以通过定制开发解决,也可以通过研发配置解决,最终可以完全脱离研发运营配置解决,本篇要描述的就是营销活动中用户参与流程或者说玩法串联的流程编排问题。
分析现状
正如前面所提到的,我们对于常用的玩法进行沉淀之后,我们获得了各类形式的抽奖、答题、任务、签到等玩法,在使用的过程中,通常是玩法A的某个动作在某种场景下关联玩法B的某个动作,比如用户第一次参与答题获得一次抽奖机会,用户任务完成获得现金等等。
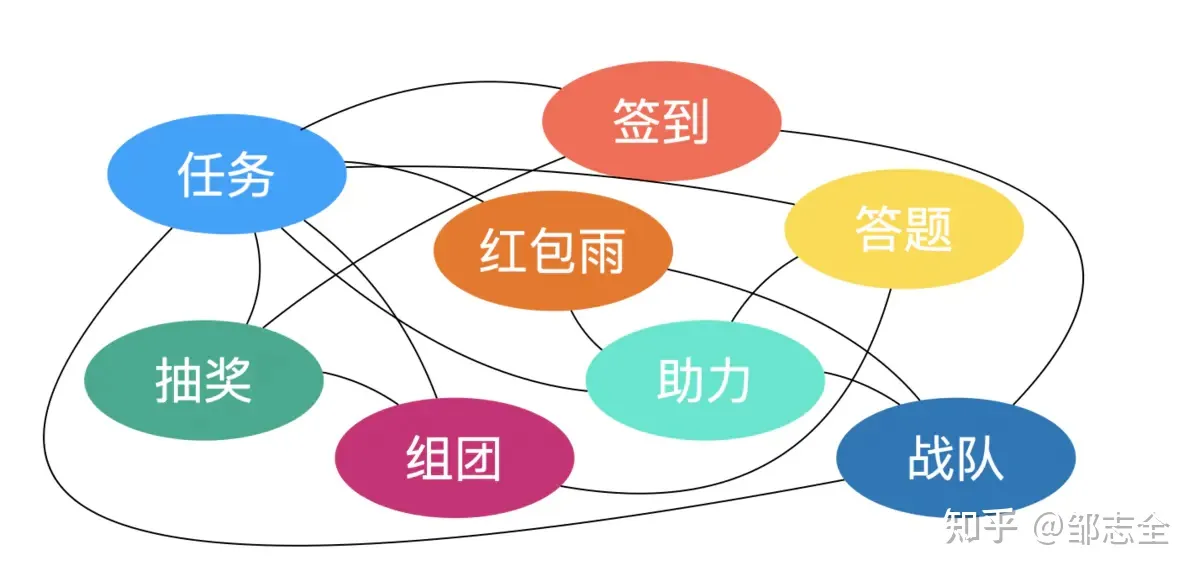
如果纯研发开发定制关联的话,每次面临开发的关系是相对复杂的 按照量级来算基本是:m*n*s (输出事件、输入动作、场景),即使每次都有沉淀,玩法和玩法的交互关系基本是过度复杂、难以维护的,所以我们需要一个“总线”工具来集中管理这些交互,降低复杂度。
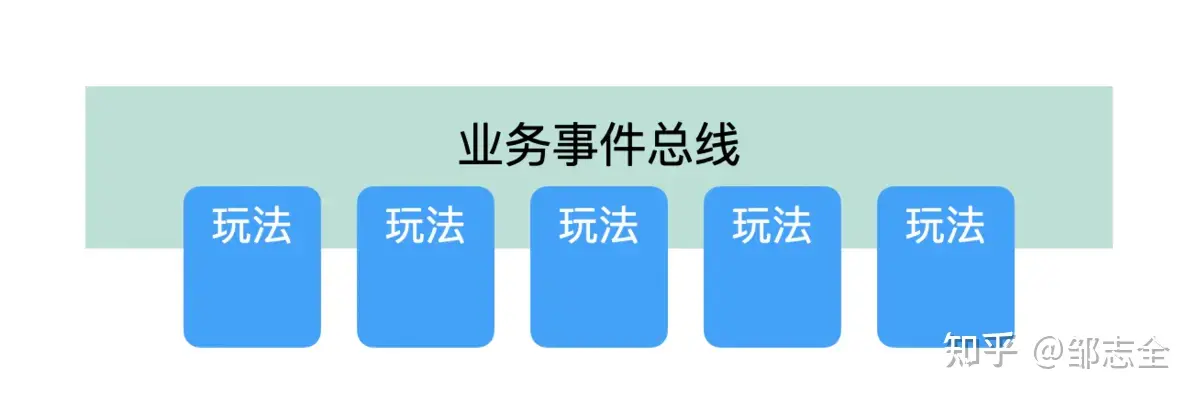
整体设计思路
对于这些易变且复杂的逻辑,最直观的思路是剥离业务决策逻辑与代码决策逻辑。在活动编排的场景下,业务逻辑是玩法事件之间的关联关系及决策关系,代码关联就是各类事件的接受、各类事件的call。
事件驱动设计
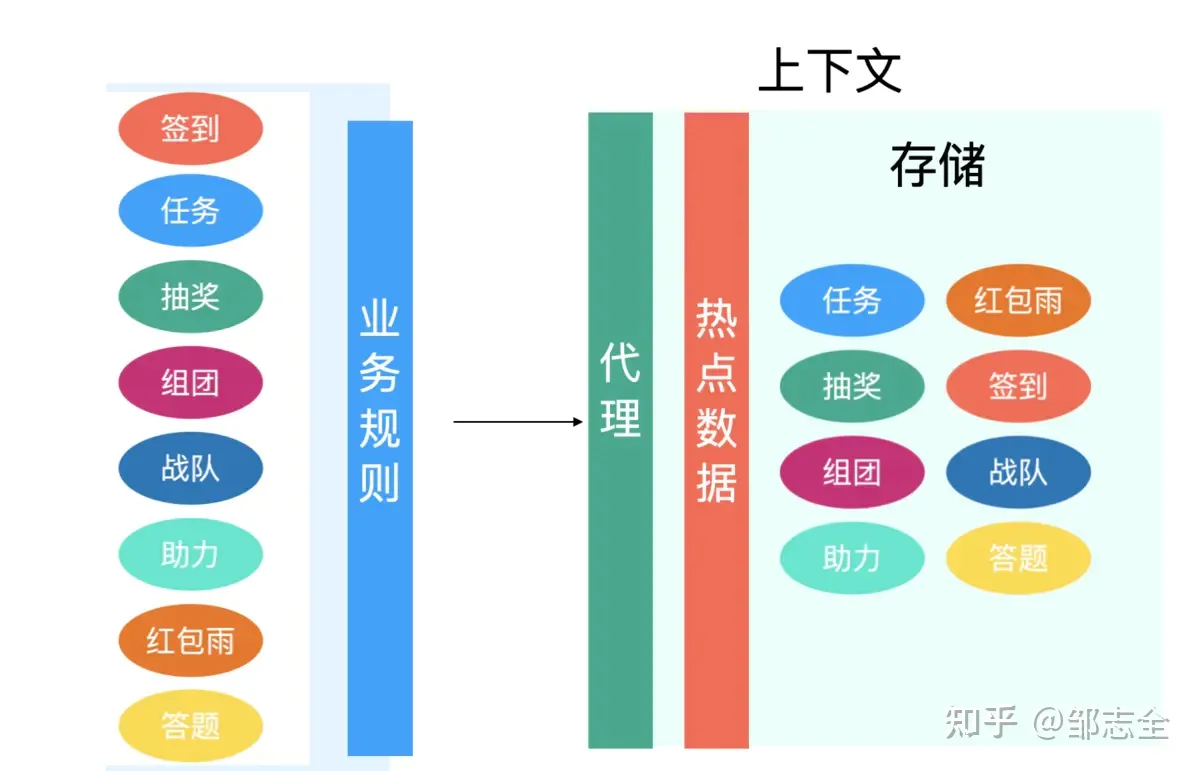
所以需要规范下玩法的输入输出,然后有一个地方能够对这些事件配置关联,对于关联之间的业务决策逻辑,只需要借鉴一下决策引擎就可以了。整个抽象完成后活动串联的成本已经从m*n*s降低到m+n,并且直接进入到研发配置关联阶段,成本至少能缩减80%以上,并未后续的运营可直接手动配置提供了功能开发的切入口。
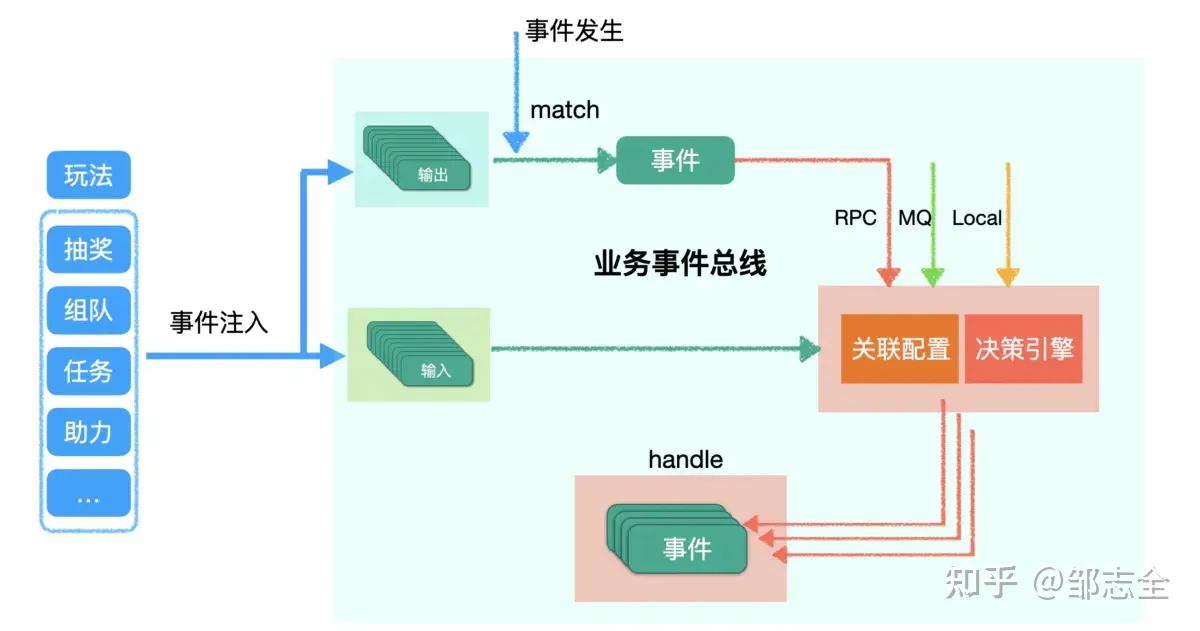
说到这里大家应该发现本质上就是一个业务事件总线,如果看过SOA事件交互总线的定义,本质上思想是一样的,只不过我们不需要SOA这么强的定义,不光是SOA架构设计中会有相关描述,如果熟知微服务架构、事件驱动架构还有DDD设计思想等,也存在大量对于事件总线设计的描述。
这里的业务事件总线不过是在这些思想之上根据活动业务场景进行本地化处理,增加了一些动态决策、配置关联的能力。
上下文共享问题
在把各种玩法解耦,然后通过业务事件总线进行玩法关联,每个玩法内部基本形成一个信息孤岛,只关心自己内部的变化,其实是不利于活动逻辑的,高门槛任务加的抽奖机会面向的奖品集合往往价值更高,不同的组团(不同身份团队成员)面向的奖励价值也是不同,很多时候需要依赖用户参与的上下文信息,如果打破信息孤岛,通常有两种处理思路:
1、把奖励这些需要上下文的玩法做成一种基础能力,感知所有玩法的上下文,奖励作为一种微内核的存在,每个玩法直接带着上下文调用。
2、进一步抽象这些感知上下文的应用,将业务规则进一步剥离,仅有业务规则(规则引擎)感知上下文信息,其他玩法的上下文对于一个玩法来说只是普通key-value而已,具体使用在 持有业务规则的表达式中执行。
整体来看两种思路本质上都是可以的,适用于不同的系统发展阶段,活动相对较多,第一种就足够了,复杂活动较多,第二种就相对适合。
整体比较来看:
第一种:实现相对简单,对玩法的要求相对较低,但是如果一个操作,同时涉及多个玩法的上下文,处理相对费劲。并且需要上下文的操作如果变多且关联,架构就逐渐退化到手动强关联。
第二种:实现相对复杂,对于玩法可配置要求较高,但扩展性较好,对于复杂活动的处理更加轻松。
上下文的设计
上下文的设计相对简单,可以粗暴的理解为一个get的路由分发,大家可以理解为一个具有业务特性的dataSource,可以根据一个key来找到我们所需要的用户参与的上下文信息。具体的实现方案可以是 一个集中存储,用来存放活动的上下文,也可以是 逻辑上的集中存储,做一层代理透过玩法注入的method活动上下文。
上下文 + 动态决策编排 = 活动编排引擎
性能保证
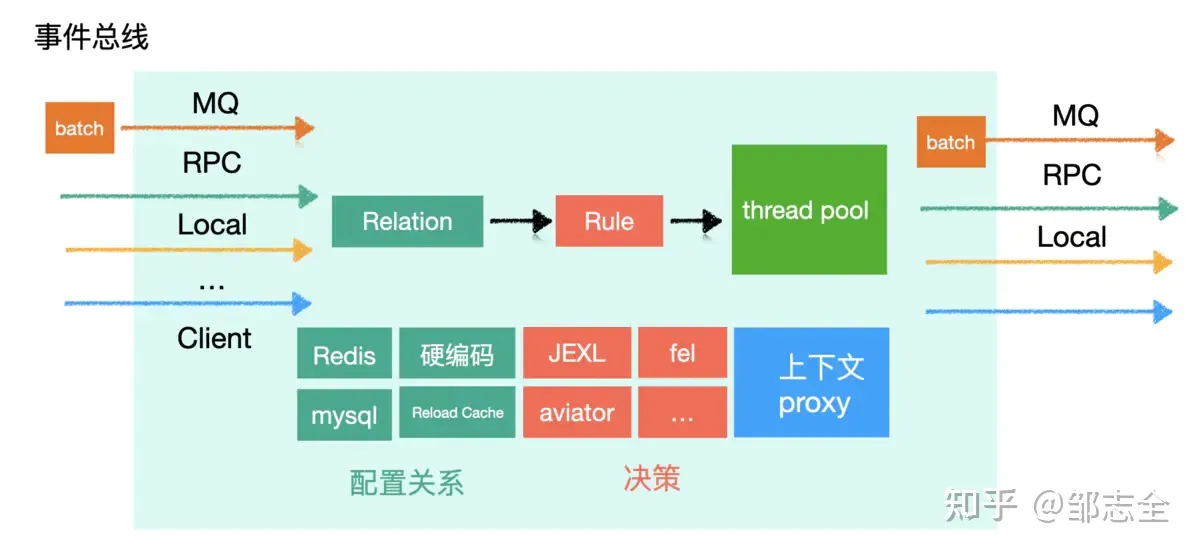
由于需要处理一个业务或者几个业务下的事件流转,业务事件总线是一个对性能要求相对较高“系统节点”,需要尽可能保证它的性能极佳的特点,这里就来说一下对于事件总线的整体优化过程(按照老套路,先优化点、再优化分布式场景下“量”),先看结果:
更少&更快的IO
对于事件总线的使用,尽可能不发生网络IO,首先对于事件总线调用的应该本地化,第二是事件总线对于外部事件的调用尽量本地化,仅作为逻辑上的模块。
如果因为扩展性、可用性等若干因素,当前的架构不允许或者不支持整个活动玩法打包到一起部署,便免不了发生IO,那就一句话,尽可能的利用epoll,这些事作为一个业务开发来说交给基础架构来处理就好啦。
更快的存储
硬编码 > 内存 > 本地磁盘 > 网络IO,常规事件之间的关联关系直接内存存储(可以DB预加载至进程内),强关联事件配置直接硬编码(硬编码的配置问题可以利用一些表达式),避免发生网络IO、磁盘IO。
合理的优化分布式下的量
事件异步化处理&微批处理这类优化吞吐的直接拿来主义,看看kafka之类的mq的优化思路,我相信大家就知道该怎么做了,像这种场景直接就别重复造轮子了,用kafka实现异步化就足够了。
平衡一致性、可用性,前面提到了尽可能利用快的存储,在分布式场景下,如果能接受多节点不一致可以用这个思路,如果一致性要求相对较高可以用单点的redis进行关联关系的存储,如果对可靠性要求很高再退一步使用mysql这些。
通常来说,事件总线总并没有显著的业务热点,横向扩容基本可以解决所有量的问题,意义需要注意的就是这个业务上的单点,做好资源隔离就可以啦。
数据一致性保证
事件总线并不是一个强业务实体,属于一个纯虚构的概念,我们只需要使用到事件总线的流程能得到保证即可。
对于分布式事务的场景,这个依赖于分布式事务的实现方案,如果是TCC类,只要保证事件能正常参与进事务中即可,对于依赖于事务型消息的分布式事务,可以替换下事件总线的“事件调用维护”,在事务消息队列上做封装即可。
对于没有分布式事务的处理场景下,最大程度利用幂等重试,做好事件处理的补单极致就好了,顺便说下,围绕“事件总线”做幂等重试是一个不错的处理思路。
现有的轮子
打开搜索引擎搜一下业务事件总线,阿里云、腾讯云都有相似的解决方案,只不是针对的业务场景相对较少,这东西并不复杂一个人两个周基本就能开发完成上线了,最重要的是对应思想的本地化实现,如果现实工作过程中遇到了相似的场景,综合评估下成本来落地就好了。
预告:《搞定营销活动-用户交互总线》,主要用来描述如何高效的维护活动同用户的交互设计,复杂的弹窗序列、主动通知一定是开发过程中最痛苦的一点,每次活动开发改需求时,最难处理的往往是这部分,下一篇就来看下如何用技术手段把这些交互问题给干掉。
